-
[Spark Streaming] PySpark 데이터프레임 모든 컬럼 json으로 변환 & 데이터프레임 딕셔너리 내부 value값 dict 변환DataProcessing/Spark 2021. 2. 25. 23:44
트위터 API로 받아오는 데이터 형태가 딕셔너리 내부에 딕셔너리가 있고, 또 리스트 value 값 안에
딕셔너리가 포함되어 있는 다중구조이므로 딕셔너리 내부 값들에 접근해야 할 필요가 있었습니다.
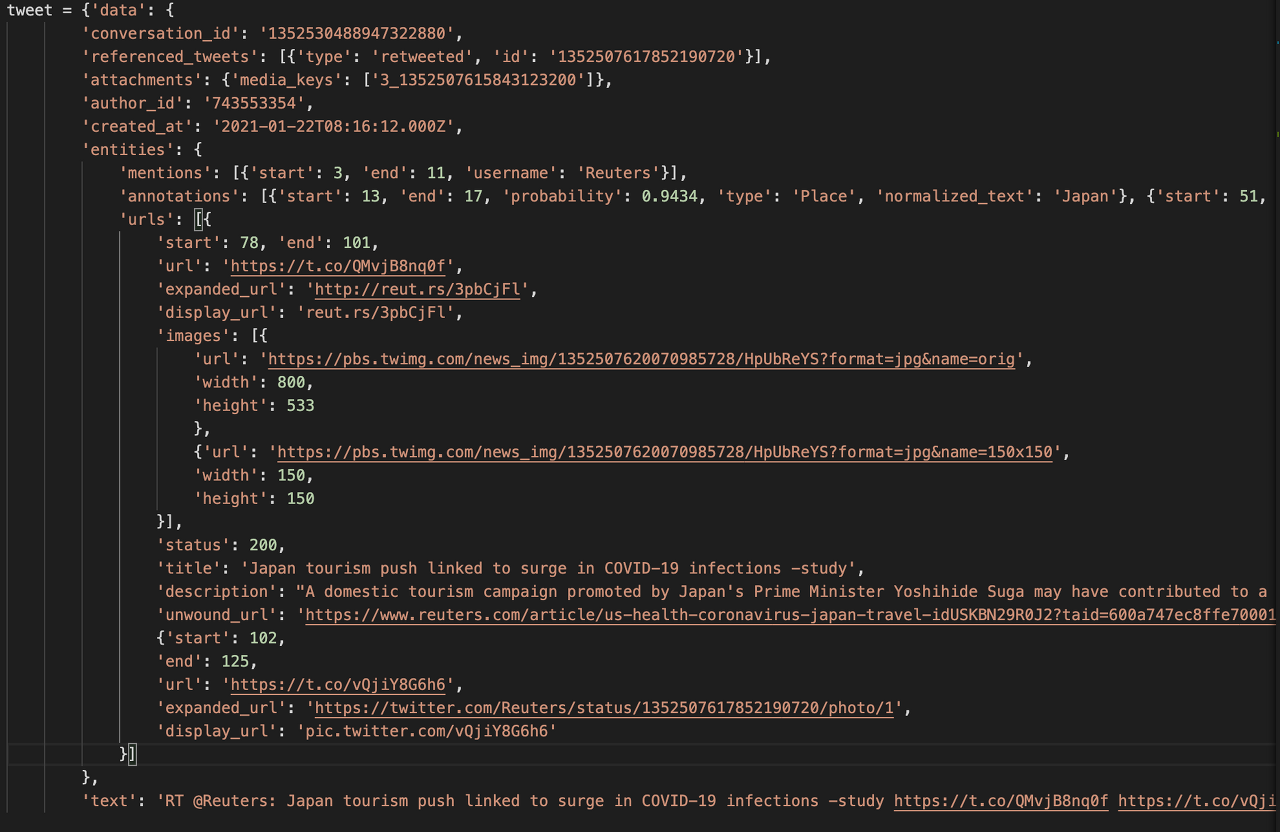
트위터 데이터 형식 따라서 먼저 Kafkaf에서 실시간으로 받아오는 데이터를 개별적 RDD로 접근하여 데이터프레임을 생성하고
데이터프레임의 컬럼(트윗 데이터 key값들)을 하나로 합친 새로운 컬럼을 생성하고 저장한 다음
다시 조회하여 딕셔너리 형태로 가공 후 내부 value값들 또한 딕셔너리로 변환하는 데이터 접근 방식을 시도했습니다.
dataframe 생성
from pyspark.sql import SparkSession
dataframe = SparkSession.createDataFrame(rdd, schema = ['col_name1', 'col_name2', ...])dataframe 내 모든 colums => 하나의 new json column으로 생성하기
df = dataframe.withColumn("jsonCol", functions.to_json(functions.struct([dataframe[x] for x in dataframe.columns])))
new json column 값 조회하기
df_to_json = df.select('jsonCol').collect() # return list type
list 값을 dictionary로 변환하기
df_to_json = df.select('jsonCol').collect()[0].asDict()
df_to_json value 값 dictionary로 변환하기
import json
df_value_to_json = json.loads(df_to_json['jsonCol'])
- 이상 오늘의 삽질일기 끝!
여기저기 삽질도 해보고
날려도 먹으면서
배우는 게
결국 남는거다
- Z.Sabziller
반응형'DataProcessing > Spark' 카테고리의 다른 글
[Spark] Pyspark 데이터프레임 Shape(column) & Size(row) 구하기 (0) 2021.03.03 [Spark] Pyspark 데이터프레임을 JSON 딕셔너리로 변환하기 (0) 2021.03.01 [Spark Streaming] spark-streaming-kafka 실행 오류 해결 (feat. 파일 경로 옮기기) (0) 2021.02.24 [Spark Streaming] Kafka-Spark Streaming-Cassandra 연동 (feat.pyspark) (0) 2021.02.23 [Spark Streaming] Kafka TransformedDStream 변환하기 (0) 2021.02.19