-
[모두를 위한 컴퓨터 과학] Ch6. 데이터 구조(Data Structure)Study/BoostCourse 2021. 11. 28. 22:32
https://www.boostcourse.org/cs112/joinLectures/41307
모두를 위한 컴퓨터 과학 (CS50 2019)
부스트코스 무료 강의
www.boostcourse.org
💃 해당 강의를 듣고 스터디용으로 정리한 내용들입니다 💃
👉 이전 강의
https://ninano1109.tistory.com/195
[모두를 위한 컴퓨터 과학] Ch5. 메모리(Memory)
https://www.boostcourse.org/cs112/joinLectures/41307 모두를 위한 컴퓨터 과학 (CS50 2019) 부스트코스 무료 강의 www.boostcourse.org 💃 해당 강의를 듣고 스터디용으로 정리한 내용들입니다 💃 👉 이전..
ninano1109.tistory.com
1) malloc과 포인터 복습
변경전
int main(void) { # point x, y 선언 int *x; int *y; # int 자료형 크기(4bit)에 따라 메모리 할당 x = malloc(sizeof(int)); # x와 y가 가리키는 지점에 42와 13 저장 *x = 42; *y = 13; }- y는 포인터로만 선언되었을 뿐, 어디를 가리킬지에 대해서는 정의되지 않음
변경후
int main(void) { # point x, y 선언 int *x; int *y; # int 자료형 크기(4bit)에 따라 메모리 할당 x = malloc(sizeof(int)); y = x; # x와 y가 가리키는 지점에 42와 13 저장 *x = 42; *y = 13; }- x가 가리키는 곳에도 동일하게 13으로 저장됨
2) 배열의 크기 조정하기
일정한 크기인 배열의 메모리를 늘리려면:
1. 직접 수동으로 옮기기
- 새로운 공간에 큰 크기의 메로리를 다시 할당함
- 기존 배열의 값들 하나씩 옮겨주기
- O(n)의 시간복잡 = 배열의 크기 n만큼 시간 소요
#include <stdio.h> #include <stdlib.h> int main(void) { //int 자료형 3개로 이루어진 list 라는 포인터를 선언하고 메모리 할당 int *list = malloc(3 * sizeof(int)); // 포인터가 잘 선언되었는지 확인 if (list == NULL) { return 1; } // list 배열의 각 인덱스에 값 저장 list[0] = 1; list[1] = 2; list[2] = 3; // int 자료형 4개 크기의 tmp 라는 포인터를 선언하고 메모리 할당 int *tmp = malloc(4 * sizeof(int)); // PC에 메모리가 부족할 경우 malloc이 메모리를 다 쓸 수 있어 안전성 점검 필요 if (tmp == NULL) { return 1; } // list의 값을 tmp로 복사 for (int i = 0; i < 3; i++) { tmp[i] = list[i]; } // tmp배열의 네 번째 값도 저장 tmp[3] = 4; // list의 메모리를 초기화 free(list); // list가 tmp와 같은 곳을 가리키도록 지정 list = tmp; // 새로운 배열 list의 값 확인 for (int i = 0; i < 4; i++) { printf("%i\n", list[i]); } // list의 메모리 초기화 free(list); }- malloc을 이용하면 정해진 숫자 타이핑 필요 없이 일정량의 메모리 동적 할당 가능
- malloc을 이용해 메모리를 할당받으면, 해당 메모리의 주소 반환
2. realloc() 함수 사용하기
#include <stdio.h> #include <stdlib.h> int main(void) { int *list = malloc(3 * sizeof(int)); if (list == NULL) { return 1; } list[0] = 1; // tmp 포인터에 메모리를 할당하고 list의 값 복사 int *tmp = realloc(list, 4 * sizeof(int)); if (tmp == NULL) { return 1; } // list가 tmp와 같은 곳을 가리키도록 지정 list = tmp; // 새로운 list의 네 번째 값 저장 list[3] = 4; // list의 값 확인 for (int i = 0; i < 4; i++) { printf("%i\n", list[i]); } //list 의 메모리 초기화 free(list); }크기가 2인 배열에서 4번째 값도 저장하고 싶을 때,

바로 뒤에 해당하는 메모리에 저장 할수도 있지만,

이처럼 보이지 않는 값들이 저장되어 있을 경우에는
데이터를 덮어씌우게 되어 해당 값을 가리키는 포인터 역할을 잃어버릴 수도 있음.
따라서 새로운 임시 메모리를 할당하여, 수동 복사/ realloc() 함수로 새로운 배열 만듬.
3) 연결 리스트: 도입
- 데이터 구조: 컴퓨터 메모리를 좀 더 효율적으로 관리하기 위해서 새롭게 정의하는 구조체
- 일종의 메모리 레이아웃, 빵부스러기/지도라고 생각할 수 있음
- 연결 리스트는 데이터 구조 중 하나
- 연결 리스트에서는 두 배의 메모리를 할당해서 각 인덱스의 메모리 주소에 자신의 값과 바로 다음 값의 주소인 포인터를 저장함
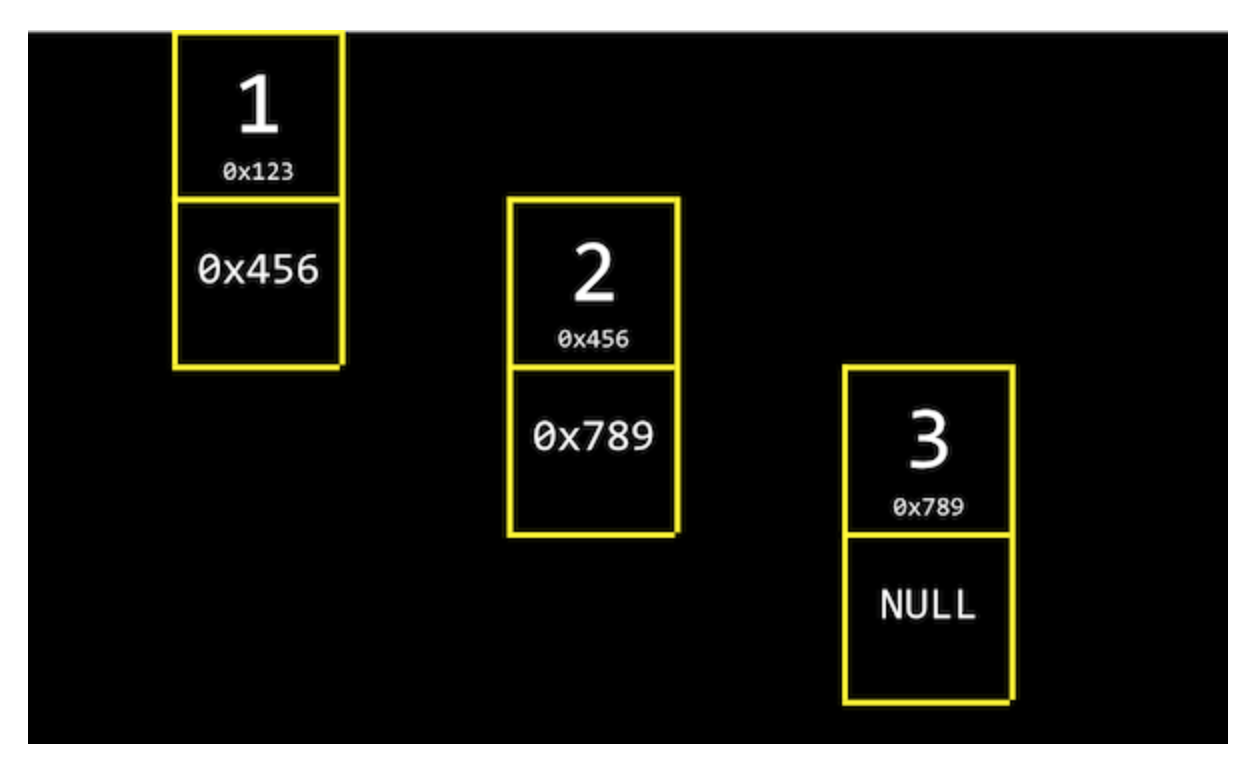
// 구조체 안에서 node를 사용하기 위함 typedef struct node { int number; struct node *next; // pointing the next node! } node;- node: 직사각형으로 나타낼 수 있는 메모리 덩어리
- node 구조체는 number와 *next 두 개 필드가 함께 정의되어 있음
- number는 각 node가 가지는 값을 의미하며, *next는 다음 node를 가리키는 포인터의 역할
// 구조체의 정식 명칭 typedef struct x { int number; struct x *next; } node; // written as alias(nickname) for the structure4) 연결 리스트: 코딩
#include <stdio.h> #include <stdlib.h> // node 구조체 정의 typedef struct node { // 정수형 변수 name 지정 int number; //다음 node의 주소를 가리키는 포인터 *next 지정 struct node *next; } node; int main(void) { // list라는 이름의 node 포인터 정의 // 현재 아무것도 가리키고 있지 않으므로 NULL로 초기화 node *list = NULL; // 새로운 node를 위해 메모리 할당한 것을 포인터 *n으로 가리킴 node *n = malloc(size(node)); if (n==NULL) { return 1; } // n의 number 값에 1 저장 = *n.number n->number=1; // n 다음 node가 없으므로 NULL로 초기화 n->next = NULL; // list 포인터를 n 포인터로 바꿔주기 list = n; // node들 추가 생성 node *n = malloc(sizeof(node)); if (n == NULL) { return 1; } n->number = 2; n->next = NULL; //이 node의 다음 node를 n 포인터로 지정하기 // list->1->2 list->next = n; node *n = malloc(sizeof(node)); if (n == NULL) { return 1; } n->number = 3; n->next = NULL; // 첫 번째 node (list)의 다음 node(list->next)의 // 다음 node(list->next->next)를 n 포인터로 지정하기 list->next->next = n; // list에 연결된 node들의 number값 차례대로 출력 for (node *tmp = list; tmp != NULL; tmp = tmp->next) { printf("%i\n", tmp->number); } // list에 연결된 node들의 메모리 해제를 위해 free 실행 while (list != NULL) { node *tmp = list->next; free(list); list = tmp; } } 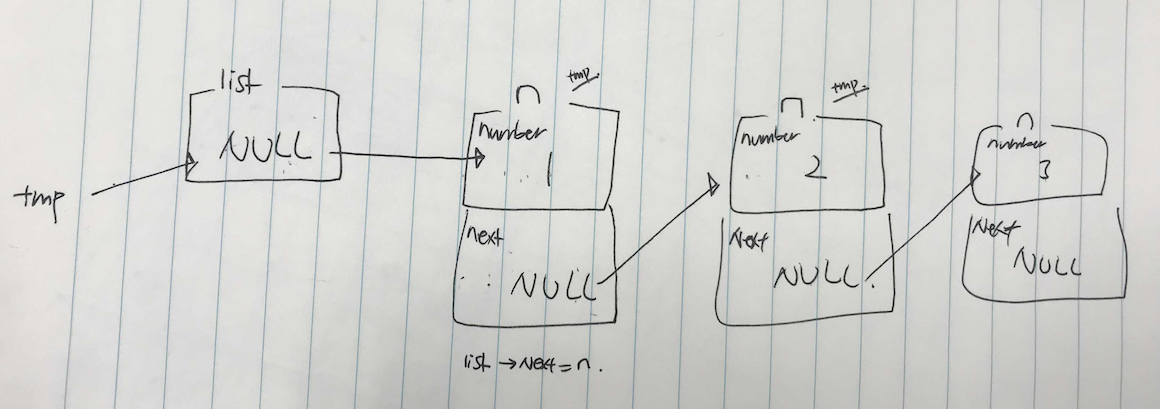
6) 연결 리스트: 트리
- 트리 = 연결 리스트를 기반으로 하는 데이터 구조
- 연결 리스트의 노드들이 1차원적으로 구성되어 있는 반면, 트리의 노드들 2차원적으로 연결되어 있음
- 각 노드는 일정한 층(같은 층으로)에 속하고 다음 하위 층의 노드를 가리키는 포인터를 가지고 있음
'이진 검색 트리'

- 가장 상위 노드(4) = 루트 노드
- 하위 노드들 = 자식 노드
- 이진 검색 트리 사용 시 검색 실행 시간 = 노드 삽입 시간 = O(log n)
이진 검색 함수
이진 검색 트리 노드 정의 typedef struct node { 노드 값 int number; 왼쪽 자식(하위) 노드 탐색 struct node *left; 오른쪽 자식(하위) 노드 탐색 struct node *right; } bool search(node *tree) { if (tree=NULL) { return false; } else if (50 < tree->number) { return search(tree->left); } else if (50 > tree->number) return search(tree->right); else { return true; } } tree->*left
이진 검색 트리의 장/단점:
- 이진 검색이 가능하므로 시간 복잡도가 O(log n)으로 줄어들어 빠르다 (연결리스트는 O(n))
- 포인터가 2배로 늘어가서 메모리 사용이 증가한다
- 오른쪽과 왼쪽의 트리 균형이 맞춰지지 않으면 효과가 없다
7) 해시 테이블
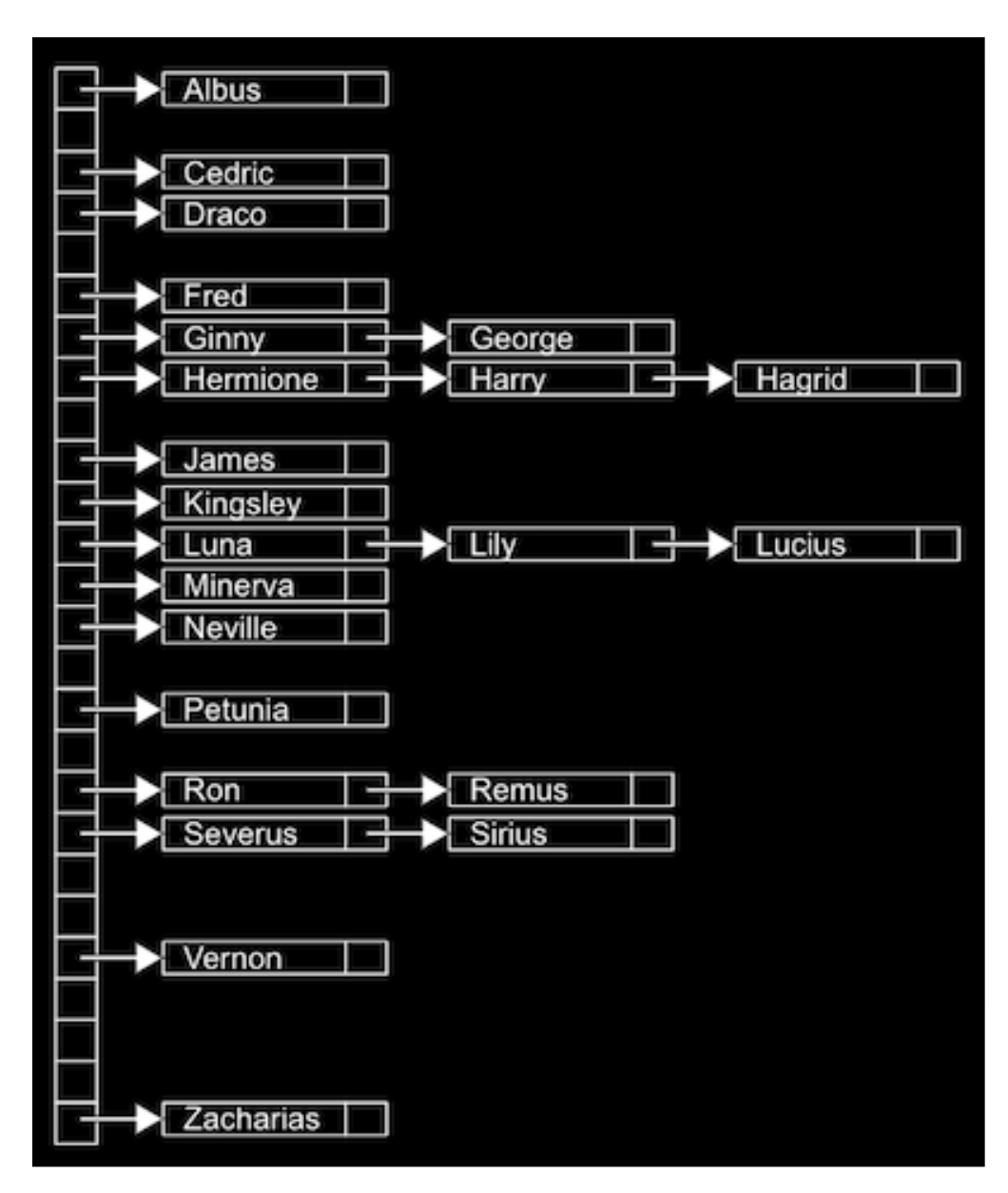
- Hash 함수란?
- input 값이 있을 때 어디로 가야할지 알려주는 함수이자 알고리즘
- 연결 리스트의 배열(연결 리스트가 담긴 여러개의 바구니) = 해시 테이블
- Hash의 목적은 일정한 실행 시간을 설계하여 O(1)를 만드는 것
- 단어의 앞 글자만 보는 알고리즘은, 글자의 중복이 있을 때 한 곳에 몰리기 때문에 효율적이지 않음 => 최대 O(n)
- 첫 두 글자 살펴보기
- 첫 세 글자 살펴보기
- ... 중복 없이 최대한 많이 담을 수 있는 바구니 만들기

- 여전히, 연결 리스트나 배열보다는 효과적
- 장점
- 적은 리소스로 많은 데이터 효율적 관리 가능
- 배열의 인덱스를 사용하여 검색, 삽입, 삭제가 가능하다 ⇒ O(1)
- key와 hash 값이 연관성이 없어보여 보안에도 많이 사용됨
- 중복 제거에 용이함
- 단점
- 공간 복잡도가 커진다
- 순서가 있는 배열에 적합하지 않음
- 해시 함수 의존도가 커진다
Hash Table VS Hash Map
- 차이점은 동기화 지원 여부
- 키에 대한 해시 값을 사용하여 저장, 조회하는 것은 동일
- Hash Table: 병렬 처리(동기화 고려)할 때, Null 값 허용하지 않음
- Hash Map: 병렬 처리하지 않을 때(동기화 고려X), Null 값 허용

8) 트라이
- 기본적으로 Tree 형태의 자료구조
- Tree와 다른점은 각 노드가 배열로 이루어져 있음
- 즉, 각각의 노드가 배열로 이루어진 Tree
- 알파벳 문자열 값을 저장한다면, 각 노드는 a~z까지 가진 배열로 이루어짐
- 배열의 각 요소는 다음 층(하위 레벨)의 노드인 a~z까지의 배열을 가리킨다
- 트라이에서 값을 검색하는데에는 '문자열의 길이'에 따라 시간이 걸린다
- 영어 단어의 길이가 n이라고 할 때, 검색 시간은 O(n) 이지만, 이름의 경우 보통 20자 이내이기 때문에, 시간 효율성은 상수 O(k) = O(1)
- 트라이의 장/담점
- 속도가 빠름 => O(1)
- 메모리 사용량의 증가 => 각 해시에 대한 모든 정보를 포함하고 있어야 하므로
- 한 글자를 저장하기 위해 26배의 메모리를 차지하고 있음
9) 스택, 큐, 딕셔너리
스택
- 후입선출 방식 (Last In First Out)
- 이메일 받은편지함, 뷔페 접시, 마트 진열 상품 등(기한이 중요한 것에서 사용)
- 배열이나 연결 리스트로 구현 가능
큐
- 선입선출 방식 (First In First Out)
- 순서가 중요한 보통의 대기줄에서 사용함(자동차 신호 대기 등)
- 배열이나 연결 리스트로 구현 가능
딕셔너리
- 'Key'와 'Value'로 이루어진 자료구조
- 'Key'에 해당하는 Value 값을 저장하고 읽어오는 것
- 알파벳 첫 글자로 값을 찾는 해시 테이블과 동일한 개념이라고 볼 수 있음
// 구조체의 정식 명칭 typedef struct x { int number; struct x *next; } node; // written as alias(nickname) for the structure
끝! 👍
반응형'Study > BoostCourse' 카테고리의 다른 글
[모두를 위한 컴퓨터 과학] Ch5. 메모리(Memory) (0) 2021.11.22 [모두를 위한 컴퓨터 과학] Ch4. 알고리즘(Algorithm) (0) 2021.11.13 [모두를 위한 컴퓨터 과학] Ch3. 배열(Array) (0) 2021.11.05 [모두를 위한 컴퓨터 과학] Ch2. C언어 (0) 2021.10.29 [모두를 위한 컴퓨터 과학] Ch1. 컴퓨팅 사고(Computational Thinking) (0) 2021.10.11